
Retrieval-augmented generation changed how enterprises use large language models. Instead of relying solely on a model's training data, RAG grounds responses in your actual documents, databases, and knowledge bases. But traditional RAG has a fundamental limitation: it treats every query the same way. A simple "what's our refund policy?" and a complex "compare the indemnification clauses across all three vendor contracts against our standard policy" both follow the identical retrieve-and-generate path. One gets a perfect answer. The other gets a superficial one riddled with missing context.
Agentic RAG solves this by embedding autonomous AI agents into the retrieval pipeline[1]. These agents don't just retrieve — they plan, reason, self-correct, and dynamically adapt their retrieval strategies based on query complexity. The results in production are compelling: Harvey AI reports a 0.2% hallucination rate serving 700+ legal clients[2], Deutsche Telekom processes over 2 million customer conversations with an 89% acceptable answer rate[3], and a major European bank saved over EUR 20 million in three years on audit and compliance using agentic RAG with knowledge graphs[4]. But the technology demands engineering discipline: Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027[5] due to escalating costs, unclear ROI, and inadequate risk controls. This guide provides engineering leaders with a pragmatic, production-focused framework for building agentic RAG systems that deliver sustained business value — covering the architectures that work, the tools that scale, and the hard-won lessons from enterprise deployments.
From Naive Retrieval to Autonomous Reasoning
The evolution from traditional RAG to agentic RAG follows a clear maturity path[6], and understanding where each approach fits is essential for making the right architectural decisions.
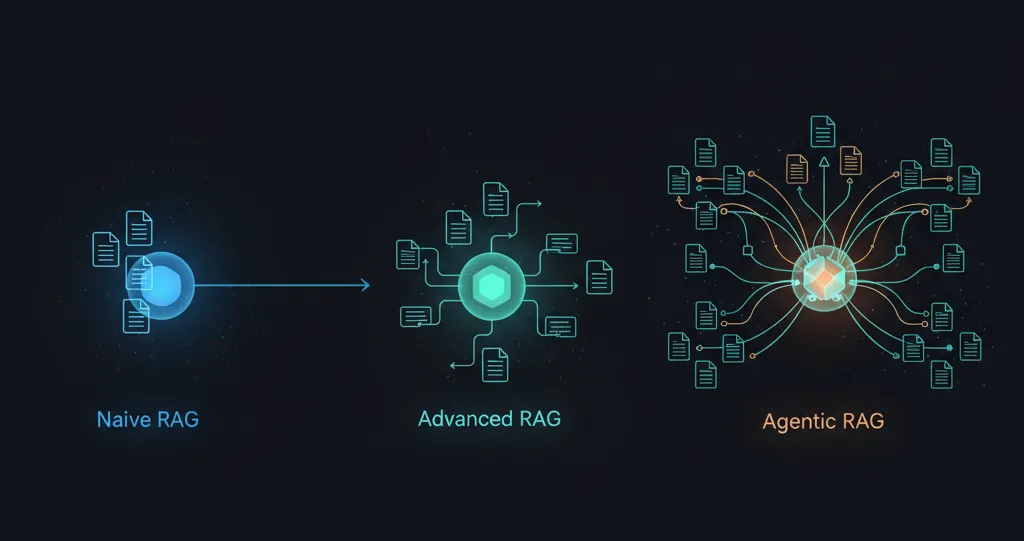
Naive RAG — the retrieve-and-read pattern that dominated 2022–2023 — follows a rigid three-step pipeline: chunk documents, retrieve the top-k most similar vectors, and feed them to an LLM for generation. It works well for simple Q&A over static knowledge bases but breaks down on multi-step questions, struggles with retrieval precision, and offers no mechanism for self-correction when it retrieves irrelevant context.
Advanced RAG introduced meaningful improvements through pre-retrieval optimizations like query expansion, rewriting, and hypothetical document embeddings (HyDE), alongside post-retrieval refinements such as reranking, context compression, and filtering. Optimized semantic chunking alone improves faithfulness scores from 0.47–0.51 to 0.79–0.82 in production benchmarks[7]. But the pipeline remains fundamentally static — a fixed sequence of operations applied identically to every query regardless of its complexity.
Agentic RAG breaks this rigidity entirely. As defined in the comprehensive January 2025 survey by Singh et al.[1], agentic RAG embeds autonomous AI agents into the RAG pipeline that leverage four core design patterns first articulated by Andrew Ng[8]: reflection (self-critique and iterative improvement), tool use (databases, APIs, and code execution alongside vector search), planning (decomposing complex tasks into executable steps), and multi-agent collaboration (coordinating specialized agents for different subtasks). The system transforms retrieval from a one-shot lookup into an iterative reasoning loop: retrieve, evaluate, re-retrieve, validate, generate.
The practical difference is profound. Where traditional RAG treats every query identically, agentic RAG dynamically adapts. A router agent classifies query complexity and selects the appropriate strategy. A corrective agent evaluates whether retrieved documents actually answer the question and triggers alternative retrieval when they don't. A planning agent decomposes complex multi-document analyses into sequences of targeted retrievals, extractions, and comparisons. Ng himself noted that agentic workflows with GPT-3.5 outperformed GPT-4 zero-shot on the HumanEval coding benchmark — jumping from 48% to 95.1%[8]. The orchestration matters more than the model.
Six Architectural Patterns That Define the Field
Production agentic RAG systems draw from a set of well-defined architectural patterns, each backed by peer-reviewed research and battle-tested framework implementations. Understanding which pattern to apply — and when to combine them — is the core architectural decision.
Router/Adaptive RAG classifies incoming queries by complexity and routes them to the appropriate retrieval strategy. The Adaptive-RAG paper by Jeong et al.[9] trains a lightweight classifier to predict whether a query needs no retrieval, single-hop retrieval, or multi-hop iterative reasoning. In production, this is the single highest-leverage optimization: query routing cuts RAG costs by 30–45% and latency by 25–40% for mixed query workloads, because the majority of queries are simple enough to skip expensive multi-step reasoning entirely.
Corrective RAG (CRAG) introduces a retrieval evaluator that assesses the relevance of retrieved documents and triggers one of three actions[10]: proceed with generation if documents are relevant, supplement with web search if they're irrelevant, or combine both approaches for ambiguous results. The key innovation is knowledge refinement — CRAG decomposes documents into individual knowledge strips, grades each one, and filters irrelevant information before it reaches the generator. LangGraph provides a production-ready CRAG implementation[11] with document relevance grading and web search fallback built in.
Self-RAG trains a single language model to adaptively retrieve passages on demand using special reflection tokens[12]: Retrieve (decides if retrieval is needed), IsRel (relevance assessment), IsSup (factual support verification), and IsUse (overall quality). Self-RAG models generated only 2% unsupported predictions versus 20% for comparable models, making it one of the most effective hallucination reduction approaches available today.
Graph RAG, pioneered by Microsoft Research[13], constructs entity knowledge graphs from source documents using LLM extraction, then applies community detection algorithms to create hierarchical clusters with pre-generated summaries. Where traditional RAG fails completely on holistic queries — "What are the main themes across this dataset?" — Graph RAG excels by enabling both local (entity-focused) and global (whole-corpus reasoning) search modes. Microsoft has open-sourced the full implementation.
Multi-Agent RAG distributes retrieval across specialized agents — one for internal documents, one for structured databases, one for web search, one for email archives — coordinated by an orchestrator agent[1]. This pattern scales horizontally: adding a new data source means adding a new agent, not rewriting the pipeline. The survey identifies three organizational structures for multi-agent systems: single-agent (centralized), multi-agent (distributed), and hierarchical (meta-agents overseeing specialized agents).
Tool-Augmented RAG gives agents access to SQL databases, APIs, code execution environments, calculators, and CRM systems alongside vector search[14]. The agent dynamically decides which tool to invoke based on the query. When a user asks "What was our Q3 revenue growth compared to competitors?", the agent might query an internal SQL database for company revenue, perform a web search for competitor earnings reports, execute Python code for the comparison calculation, and generate a synthesis. LlamaIndex's Agentic Document Workflows[15] take this further by combining document processing, structured extraction, retrieval, and agentic orchestration into end-to-end knowledge work automation.
The Production Gauntlet: Latency, Cost, and Compounding Failure
Moving agentic RAG from prototype to production exposes challenges that don't exist in traditional RAG. The core tension is that every agentic capability — routing, evaluation, self-correction, multi-step reasoning — adds LLM inference calls, and these compound in both cost and failure probability.
Latency and cost scale multiplicatively. Each additional reasoning step adds 200–500ms for embedding and vector search, plus LLM inference time. IBM notes that agentic approaches introduce greater expenses and latency as more agents participate in processing[16]. A system with four reasoning steps at 95% reliability per step delivers only 81.5% end-to-end reliability — meaning nearly one in five queries fails somewhere in the chain. This is the fundamental math that makes production agentic RAG hard.
Intelligent model routing is the most effective cost mitigation. RouteLLM from LMSYS achieves cost reductions of over 85% on benchmarks while maintaining 95% of GPT-4's quality by routing simple queries to smaller models[17]. Semantic caching through tools like Redis or GPTCache delivers 15x speed improvements for repeated or semantically similar queries[18]. These aren't optional optimizations — they're prerequisites for viable production economics.
Hallucination risk changes character in agentic systems. Traditional RAG hallucinations are relatively contained: the model fabricates information based on irrelevant context. Agentic hallucinations compound across steps — a routing error sends the query to the wrong retrieval strategy, which returns irrelevant documents, which the generator hallucinates over. Research shows integrating retrieval-based techniques reduces hallucinations by 42–68%[19], and Self-RAG achieves hallucination rates as low as 5.8% in clinical benchmarks[20]. But this requires deliberate architectural investment in grounding, citation verification, and confidence scoring at every step.
Evaluation demands fundamentally different approaches. Traditional NLP metrics like BLEU and F1 don't capture multi-step reasoning quality, tool invocation accuracy, or agent decision-making. The industry has converged on two primary open-source evaluation frameworks[21]. RAGAS[22] provides reference-free metrics — faithfulness, answer relevancy, context precision, context recall — using LLM-as-a-judge evaluation. DeepEval extends this with 50+ research-backed metrics including tool correctness and task completion, plus native Pytest integration for CI/CD pipelines. Production teams should target retrieval precision ≥ 70%, generation groundedness ≥ 90%, and end-to-end task success ≥ 85%.
Observability is non-negotiable. Multi-step agent workflows create debugging challenges that don't exist in traditional software. LangSmith provides end-to-end tracing with deep LangGraph integration. Arize Phoenix offers OpenTelemetry-native observability with auto-instrumentation for all major frameworks. Langfuse provides a fully open-source alternative with self-hosting as a first-class option. The minimum observability stack tracks per-span latency, token counts, cost, retrieval similarity scores, and automated quality evaluations on production traces.
Enterprise Case Studies: Agentic RAG in Action
The strongest evidence for agentic RAG comes from production deployments delivering measurable results across industries. These aren't research prototypes — they're systems processing millions of queries with documented ROI.
Harvey AI in legal services[2] is the defining case study. Serving 700+ clients across 45 countries, Harvey deploys agentic RAG with multi-source retrieval across user-uploaded files, vault projects, and third-party legal databases. At Allen & Overy Shearman, 4,000+ lawyers save an average 2–3 hours per week, with a 30% reduction in contract review time and 7-hour average savings on complex document analysis. Their custom legal embedding model reduces irrelevant results by approximately 25% compared to off-the-shelf embeddings, and a multi-layered verification system achieves a reported 0.2% hallucination rate. Thomson Reuters' CoCounsel[23], built on its $650M Casetext acquisition, launched agentic workflows in 2025 capable of reviewing up to 10,000 documents in bulk — tasks that would occupy an associate for the better part of a day.
Deutsche Telekom in customer support[3] built LMOS (Language Model Operating System), arguably the largest multi-agent AI deployment in Europe, serving approximately 100 million customers across 10 countries. Their agentic RAG system processes over 2 million conversations with an 89% acceptable answer rate and reduced agent development time from 15 days to just 2. Their RAN Guardian Agent for network management cuts troubleshooting from approximately one hour to a few minutes, with 75% of actions fully autonomous[24].
Financial services deployments focus on grounding and attribution. A major European bank using agentic RAG with curated ontologies saved over EUR 20 million in three years on audit and compliance, with GraphRAG achieving search precision up to 99%[4]. Bloomberg's research team discovered that RAG can paradoxically make LLMs less safe and reliable — a critical finding that led them to develop a finance-specific AI content risk taxonomy and build transparent attribution into every RAG-powered response.
Healthcare deployments are earlier-stage but show striking accuracy gains. A GPT-4 LLM-RAG system for surgical fitness assessment achieved 96.4% accuracy versus 86.6% for human-generated responses with zero hallucinations[20]. Self-reflective RAG reduced hallucinations to 5.8% in clinical decision support across 250 patient vignettes. However, the field remains largely in pilot stage with HIPAA compliance, explainability, and standardized evaluation as unresolved challenges[25].
The failure rate deserves equal attention. Industry estimates suggest 72% of enterprise RAG implementations fail or significantly underdeliver in their first year[26]. The most common failure points include missing content, poor document ranking, context window limitations, and extraction failures[27]. The most damaging enterprise anti-pattern is monolithic knowledge architecture — dumping all company knowledge into a single vector database when different content types require different retrieval strategies, access controls, and precision thresholds.
The 2026 Framework and Platform Landscape
The tooling ecosystem has matured rapidly, with clear leaders emerging across orchestration, retrieval, evaluation, and observability.

For agentic orchestration, LangGraph[28] leads enterprise rankings with graph-based workflow design supporting cyclic workflows, state persistence, human-in-the-loop interactions, and checkpointing — companies like LinkedIn, Uber, and J.P. Morgan run it in production. LlamaIndex[29] excels at data ingestion and document AI, with its Agentic Document Workflows and LlamaParse providing best-in-class complex document processing. Haystack by deepset[30] is the top choice for regulated industries, offering explicit serializable pipelines ideal for auditing and compliance — notable users include Apple, Meta, and the German Federal Ministry. CrewAI provides the most beginner-friendly multi-agent framework with role-based architecture, while Microsoft's AutoGen (used by 40% of Fortune 100) offers the deepest conversation-centric agent patterns[31]. DSPy from Stanford[32] takes a fundamentally different approach — treating LLMs as programmable components and automatically optimizing prompts, demonstrating 10% quality improvements on RAG benchmarks through automated optimization.
For cloud platforms, Azure AI Foundry leads enterprise integration with Microsoft 365 connectivity and HIPAA compliance. AWS Bedrock offers multi-vendor model access with AgentCore for full-scale agent management[33]. Google Vertex AI provides the strongest multimodal capabilities and the most developer-centric Agent Development Kit. Cohere differentiates with native citation quality controls and grounded generation built directly into its Command R models — a meaningful advantage for enterprise RAG where attribution is non-negotiable.
Vector database selection hinges on operational requirements[34]: Pinecone for zero-ops managed deployment with hybrid search, Weaviate for multi-tenancy and flexible schema, Qdrant for memory efficiency and performance with its Rust-based architecture, and Milvus for billion-scale deployments with GPU-accelerated indexing.
For evaluation, the RAGAS and DeepEval combination covers most production needs[21]. RAGAS provides lightweight reference-free scoring for continuous monitoring. DeepEval adds Pytest-native CI/CD integration, agent-specific metrics including tool correctness and task completion, and red-teaming across 40+ safety vulnerabilities. Production teams should integrate these as automated quality gates in deployment pipelines.
Best Practices: The Crawl-Walk-Run Playbook
The most reliable path to production agentic RAG follows a deliberate maturity progression — not a leap to multi-agent orchestration on day one.
Start with basic RAG and prove retrieval quality first. The crawl stage focuses on simple LLM wrappers and prompt engineering. The walk stage introduces RAG with vector databases and hybrid search. The run stage adds agentic capabilities and multi-agent systems[35]. The critical gate between walk and run is retrieval quality: if your basic RAG pipeline can't achieve precision@10 ≥ 70% and generation groundedness ≥ 90%, adding agents will amplify problems, not solve them. Jerry Liu (LlamaIndex CEO) advises starting with the simplest agentic form — a router — then adding tool calling, then multi-step reasoning, then multi-document agents[36].
Design modular architecture from the start. Separate the orchestration layer (intent classification, routing, workflow coordination), execution layer (RAG pipeline, tool executions, LLM inference), and infrastructure layer (model management, vector databases, observability). This separation enables independent scaling, easier debugging, and component-level testing. A practical 90-day deployment plan: weeks 1–2 for selecting one workflow with clear ROI and bounded blast radius; weeks 3–6 for building a minimal agent chain with 2 data sources plus policy checks; weeks 7–12 for instrumenting with LLMOps, adding evaluations, and running a supervised pilot.
Make cost optimization architectural, not afterthought. The three highest-leverage techniques are model routing (87% cost reduction by directing 90% of queries to lightweight models[17]), semantic caching (15x speed improvement for repeated queries), and token optimization (output tokens cost 3–5x more than input — controlling response length through prompt engineering delivers 20–40% token reduction[37]). Self-hosting open-source models can reduce monthly costs from $6,000 to $1,000 for comparable workloads with a 5-month hardware payback.
Put evaluation in CI/CD, not just notebooks. Automate RAGAS or DeepEval metrics as quality gates in deployment pipelines[38]. Build golden datasets with manually verified contexts and answers. Set minimum thresholds that block deployment when breached. Run shadow testing where new configurations process real queries in parallel without affecting users. Implement gradual rollouts — 1% traffic with 24-hour monitoring before scaling to 5%, 25%, 50%, and full deployment.
Know when agentic RAG is overkill. If queries are simple and single-step, the knowledge base is static and well-defined, query patterns are predictable, and the cost of wrong answers is low — traditional RAG with hybrid search and reranking will deliver 80% of the value at 20% of the complexity and cost[16]. Agentic RAG earns its complexity only when workflows genuinely require multi-step reasoning across heterogeneous data sources, high-stakes accuracy with multi-source verification, or adaptive behavior across unpredictable query types.
Moving Forward: The Market Signals and What They Mean
The quantitative case for agentic RAG is building rapidly. The RAG market stands at approximately $1.9 billion in 2025, growing at 38–49% CAGR to $10–11 billion by 2030[39]. The broader agentic AI market is projected to reach $140–199 billion by 2034[40]. McKinsey's 2025 State of AI survey found that 62% of organizations are at least experimenting with AI agents, with 23% actively scaling[41]. Gartner predicts 40% of enterprise applications will feature task-specific AI agents by 2026, up from under 5% in 2025[42].
But adoption remains asymmetric. While 95% of U.S. companies now use generative AI, only 17% attribute 5% or more of EBIT to AI[41]. The gap between experimentation and measurable business impact is the central challenge — and it is fundamentally an engineering challenge, not a model capability challenge.
The winning approach is not to adopt every architectural pattern simultaneously. It is to start with proven retrieval quality, add routing as the first agentic capability, instrument evaluation and observability from day one, and evolve toward multi-agent orchestration only when the business problem genuinely demands it. The frameworks are mature — LangGraph, LlamaIndex, and Haystack are production-proven. The evaluation tooling works — RAGAS and DeepEval provide CI/CD-ready quality gates. The cost optimization techniques are documented — model routing and semantic caching alone can reduce costs by 85%+.
What remains scarce is the engineering judgment to make the right architectural trade-offs for each specific enterprise context: which pattern, which framework, which level of agentic sophistication, and — critically — when traditional RAG is the right answer. That judgment, applied systematically, is what separates the 28% that succeed from the rest.
Looking to build production-grade agentic RAG for your enterprise? Let's discuss how Aliac can help architect retrieval systems that reason over your data — with the right patterns, frameworks, and evaluation discipline to deliver in production.
Sources & References
- [1] Singh, A. et al. (2025). "Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG." arXiv:2501.09136. https://arxiv.org/abs/2501.09136
- [2] Harvey AI (2025). "Enterprise-Grade RAG Systems." https://www.harvey.ai/blog/enterprise-grade-rag-systems
- [3] InfoWorld (2025). "How Deutsche Telekom Designed AI Agents for Scale." https://www.infoworld.com/article/4018349/how-deutsche-telekom-designed-ai-agents-for-scale.html
- [4] Squirro (2025). "RAG in 2025: Bridging Knowledge and Generative AI." https://squirro.com/squirro-blog/state-of-rag-genai
- [5] Gartner (2025). "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
- [6] MarkTechPost (2024). "Evolution of RAGs: Naive RAG, Advanced RAG, and Modular RAG Architectures." https://www.marktechpost.com/2024/04/01/evolution-of-rags-naive-rag-advanced-rag-and-modular-rag-architectures/
- [7] Zilliz (2024). "Native RAG vs. Advanced RAG vs. Modular RAG." https://zilliz.com/blog/advancing-llms-native-advanced-modular-rag-approaches
- [8] Ng, A. (2024). "The Rise of AI Agents: Redefining Automation and Innovation." Referenced via multiple sources including DeepLearning.AI course materials. https://www.deeplearning.ai/short-courses/building-agentic-rag-with-llamaindex/
- [9] Jeong, S. et al. (2024). "Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity." arXiv:2403.14403. https://arxiv.org/abs/2403.14403
- [10] Greyling, C. (2024). "Corrective RAG (CRAG)." https://cobusgreyling.medium.com/corrective-rag-crag-5e40467099f8
- [11] LangGraph Documentation. "Corrective RAG (CRAG)." https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_crag/
- [12] Asai, A. et al. (2023). "Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection." arXiv:2310.11511, ICLR 2024 Oral. https://www.projectpro.io/article/self-rag/1176
- [13] Microsoft Research (2024). "GraphRAG: Unlocking LLM Discovery on Narrative Private Data." https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
- [14] Weaviate (2024). "What Is Agentic RAG? From LLM RAG to AI Agents." https://weaviate.io/blog/what-is-agentic-rag
- [15] LlamaIndex (2025). "Agentic Document Workflows: A Practical Guide." https://www.llamaindex.ai/blog/introducing-agentic-document-workflows
- [16] IBM. "What is Agentic RAG?" https://www.ibm.com/think/topics/agentic-rag
- [17] LMSYS Org (2024). "RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing." https://lmsys.org/blog/2024-07-01-routellm/
- [18] Redis (2025). "Agentic RAG: How Enterprises Are Surmounting the Limits of Traditional RAG." https://redis.io/blog/agentic-rag-how-enterprises-are-surmounting-the-limits-of-traditional-rag/
- [19] Voiceflow (2025). "How to Prevent LLM Hallucinations: 5 Proven Strategies." https://www.voiceflow.com/blog/prevent-llm-hallucinations
- [20] MDPI Electronics (2024). "Evaluating RAG Variants for Clinical Decision Support: Hallucination Mitigation and Secure On-Premises Deployment." https://www.mdpi.com/2079-9292/14/21/4227
- [21] Gocodeo (2025). "Top 5 AI Evaluation Frameworks in 2025: From RAGAS to DeepEval and Beyond." https://www.gocodeo.com/post/top-5-ai-evaluation-frameworks-in-2025-from-ragas-to-deepeval-and-beyond
- [22] Es, S. et al. (2023). "RAGAS: Automated Evaluation of Retrieval Augmented Generation." arXiv:2309.15217. https://arxiv.org/abs/2309.15217
- [23] Legal IT Insider (2025). "Thomson Reuters Launches CoCounsel Legal with Agentic AI and Deep Research Capabilities." https://legaltechnology.com/2025/08/05/thomson-reuters-launches-cocounsel-legal-with-agentic-ai-and-deep-research-capabilities/
- [24] Deutsche Telekom (2025). "AI Agents for Mobile Network." https://www.telekom.com/en/media/media-information/archive/ai-agents-for-mobile-network-1099054
- [25] medRxiv (2025). "Bridging AI and Healthcare: A Scoping Review of Retrieval-Augmented Generation." https://www.medrxiv.org/content/10.1101/2025.04.01.25325033v1.full.pdf
- [26] RAG About It (2025). "Why 72% of Enterprise RAG Implementations Fail in the First Year." https://ragaboutit.com/why-72-of-enterprise-rag-implementations-fail-in-the-first-year-and-how-to-avoid-the-same-fate/
- [27] Galileo AI (2025). "Mastering RAG: How To Architect An Enterprise RAG System." https://galileo.ai/blog/mastering-rag-how-to-architect-an-enterprise-rag-system
- [28] LangChain Blog (2025). "Reflections on Three Years of Building LangChain." https://blog.langchain.com/three-years-langchain/
- [29] LlamaIndex GitHub. "LlamaIndex: The Leading Framework for Building LLM-Powered Agents Over Your Data." https://github.com/run-llama/llama_index
- [30] AlphaCorp AI (2025). "RAG Frameworks: Top 5 Picks for Enterprise AI." https://alphacorp.ai/top-5-rag-frameworks-november-2025/
- [31] AryaXAI (2025). "Comparing Modern AI Agent Frameworks: AutoGen, LangChain, OpenAI Agents, CrewAI, and DSPy." https://www.aryaxai.com/article/comparing-modern-ai-agent-frameworks-autogen-langchain-openai-agents-crewai-and-dspy
- [32] DSPy. "DSPy: Programming—not prompting—Language Models." https://dspy.ai/
- [33] Ardor (2025). "Cloud Platforms for AI Agents: A Comparison Guide." https://ardor.cloud/blog/cloud-platforms-for-ai-agents-a-comparison-guide
- [34] LiquidMetal AI (2025). "Vector Database Comparison: Pinecone vs Weaviate vs Qdrant vs FAISS vs Milvus vs Chroma." https://liquidmetal.ai/casesAndBlogs/vector-comparison/
- [35] Towards Data Science (2025). "Six Lessons Learned Building RAG Systems in Production." https://towardsdatascience.com/six-lessons-learned-building-rag-systems-in-production/
- [36] DeepLearning.AI (2024). "Building Agentic RAG with LlamaIndex." https://www.deeplearning.ai/short-courses/building-agentic-rag-with-llamaindex/
- [37] Koombea (2025). "LLM Cost Optimization: Complete Guide to Reducing AI Expenses." https://ai.koombea.com/blog/llm-cost-optimization
- [38] Anyscale Documentation. "RAG Evaluation." https://docs.anyscale.com/rag/evaluation
- [39] MarketsandMarkets (2025). "Retrieval-Augmented Generation (RAG) Market Worth $9.86 Billion by 2030." https://www.prnewswire.com/news-releases/retrieval-augmented-generation-rag-market-worth-9-86-billion-by-2030--marketsandmarkets-302580695.html
- [40] Market.us (2025). "Agentic AI Market Size, Share, Trends | CAGR of 43.8%." https://market.us/report/agentic-ai-market/
- [41] McKinsey & Company (2025). "The State of AI in 2025: Agents, Innovation, and Transformation." https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
- [42] Gartner (2025). "Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026." https://www.gartner.com/en/newsroom/press-releases/2025-08-26-gartner-predicts-40-percent-of-enterprise-apps-will-feature-task-specific-ai-agents-by-2026-up-from-less-than-5-percent-in-2025